-
넘파이(NumPy)개발/데이터분석 2024. 9. 16. 14:40반응형
넘파이(NumPy)

axis0 == column(열), axis1==row(행) - axis: 배열의 각 축
- rank: 축의 개수
- shape: 축의 길이, 배열의 크기
배열 만들기
- np.array() 함수를 사용해서 배열을 만듭니다.
- 대부분 리스트로부터 배열을 만들거나, 머신러닝 관련 함수 결과값이 배열이 됩니다.

차원 확인
- ndim 속성으로 배열 차원을 확인
ex) data.ndim
# 배열 만들기 arr = np.array([10, 11, 12, 13, 14, 15]) # 확인 print(arr) # 정보 확인 print(arr.ndim) print(arr.shape) print(arr.dtype)Reshape
- 배열을 사용할 때 다양한 형태(Shape)로 변환할 필요가 있음
- 배열에 포함된 요소가 사라지지 않는 형태라면 자유롭게 변환할 수 있음
- (3, 4) → (2, 6) → (4, 3) → (12, 1) → (6, 2) 등등 요소 개수만 변하지 않으면 됨
- reshape(m, -1) 형태로 지정하여 Reshape 가능
인덱싱
a[[0], [1]]는 배열에서 0번째 행과 1번째 열에 해당하는 값
배열연산
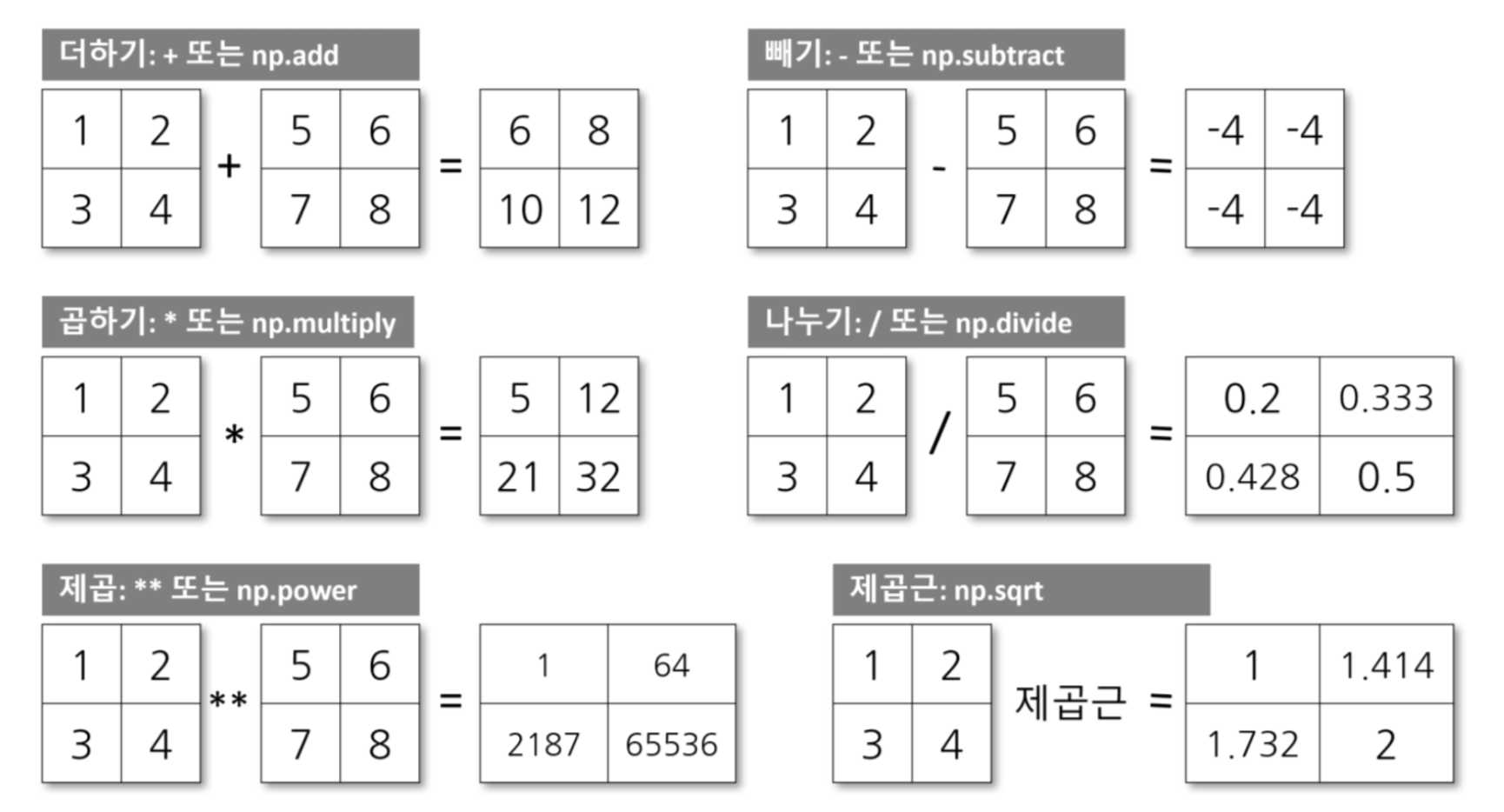
더하기
# 배열 더하기 print(x + y) # 또는 print(np.add(x, y))빼기
# 배열 빼기 print(x - y) # 또는 print(np.subtract(x, y))나누기
# 배열 나누기 print(x / y) # 또는 print(np.divide(x, y))곱하기
# 배열 곱하기 print(x * y) # 또는 print(np.multiply(x, y))지수연산
# 배열 y 제곱 print(x ** y) # 또는 print(np.power(x, y))배열집계
- np.sum(), 혹은 array.sum()
- axis = 0 : 열 기준 집계
- axis = 1 : 행 기준 집계
- 생략하면 : 전체 집계
- 동일한 형태로 사용 가능한 함수 : np.max(), np.min, np.mean(), np.std()
a = np.array([[1,5,7],[2,3,8]]) print(a) # 전체 집계 print(np.sum(a)) # 열기준 집계 print(np.sum(a, axis = 0)) # 행기준 집계 print(np.sum(a, axis = 1))그 외의 함수
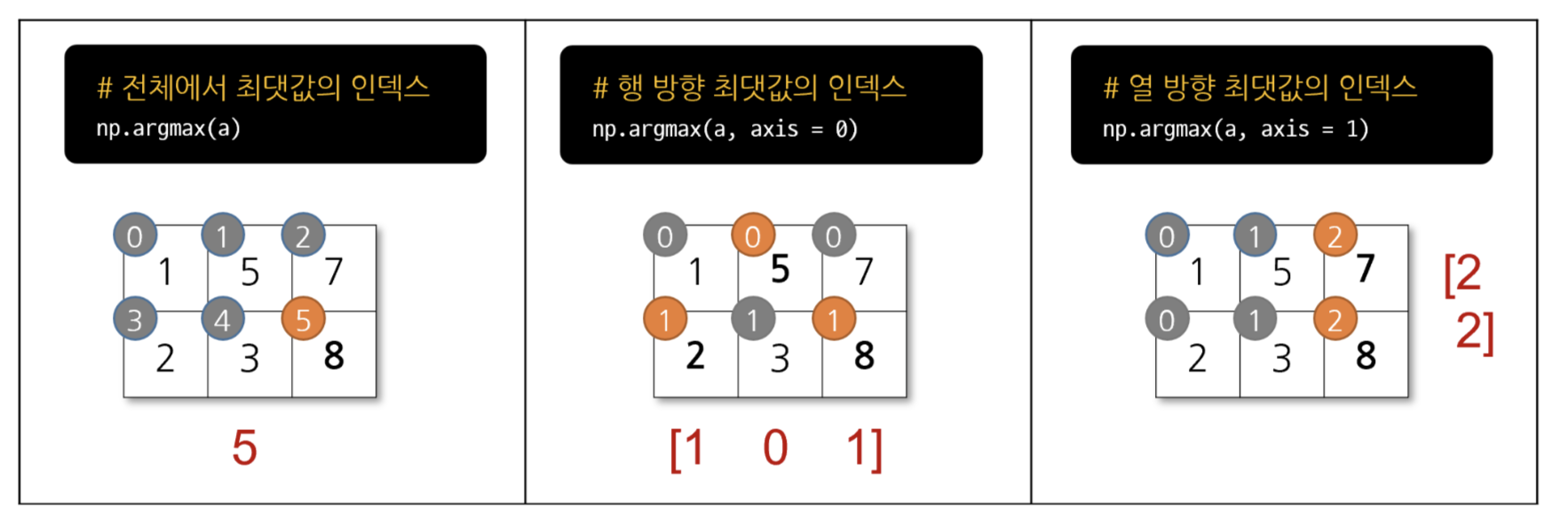
- np.where(조건문, true일때 값, false일때 값)
# 선언 a = np.array([1,3,2,7]) # 조건 np.where(a > 2, 1, 0)결과값
array([0, 1, 0, 1])np_arr.mean() 객체 지향적인 접근
- NumPy 배열 객체인 `np_arr`의 메서드를 호출하는 방식
- NumPy 배열 객체는 자체적으로 평균을 계산하는 `mean()` 메서드를 가지고 있으므로, 객체 자체에서 바로 평균을 계산할 수 있음import numpy as np np_arr = np.array([1, 2, 3, 4, 5]) print(np_arr.mean()) # 출력: 3.0
np.mean(np_arr) 함수 지향적인 접근
- NumPy 모듈의 함수인 `mean()`을 사용하는 방식
- NumPy 모듈에서 제공하는 함수에 배열 `np_arr`을 인자로 전달하여 평균을 계산합니다.import numpy as np np_arr = np.array([1, 2, 3, 4, 5]) print(np.mean(np_arr)) # 출력: 3.0반응형'개발 > 데이터분석' 카테고리의 다른 글
넘파이(NumPy) vs 판다스(Pandas) (3) 2024.09.16 Numpy 배열 객체 (1) 2022.08.31